What it is?¶
- black box global optimization
Bayes rule¶
$P(A|B) = \frac{P(B|A) P(A)}{P(B)}$
- $P(A|B)$ - posterior probability
- $P(B|A)$ - likelihood
- $P(A)$ - prior probability
- $P(B)$ - marginal likelihood
$P(A|B) \propto P(B|A) P(A)$
Bayesian Inference¶
$P(H|E) = \frac{P(E|H) P(H)}{P(E)}$
- $P(H|E)$ - probability of hypothesis given evidence
- $P(E|H)$ - probability of observing evidence given hypothesis
- $P(H)$ - probability of hypothesis before observing any data
$P(H|E) \propto P(E|H) P(H)$
Functions are samples from random processes¶
- Random process is a generalization of multivariate distribution
(for more information refer to MI-SPI)
Multivariate normal distribution¶
- $f(x_{1},\ldots ,x_{k})={\frac {1}{{\sqrt {(2\pi )^{{k}}|{\boldsymbol \Sigma }|}}}}\exp \left(-{\frac {1}{2}}({{\mathbf x}}-{{\boldsymbol \mu }})^{{\mathrm {T}}}{{\boldsymbol \Sigma }}^{{-1}}({{\mathbf x}}-{{\boldsymbol \mu }})\right)$
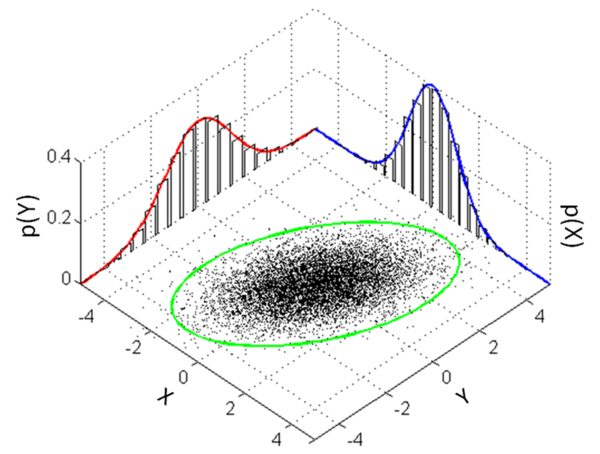
Gaussian Process¶
- $\mu$ and $\sigma$ are functions ($\sigma$ is usually renamed to $\mathbf{K}$)
- any finite sample from $\mathcal{GP}$ is a multivariate normal distribution with same dimension as size of the sample
- $\mathbf{K}(x,x')$ can be any positive-definite function (same as kernel functions)
- but usual choise is
- squared exponential $\exp\left(-\frac{1}{2l}(x-x')^2\right)$
- squared exponential $\text{ARD}^*$ $\exp\left(-\frac{1}{2}(x-x')^T\mathrm{diag}(\theta)^{-2}(x-x')\right)$
- Matérn 3/2 or 5/2
- in a case of dot product GP is equivalent with ridge regression
- but usual choise is
* ARD stands for automatic relevance determination
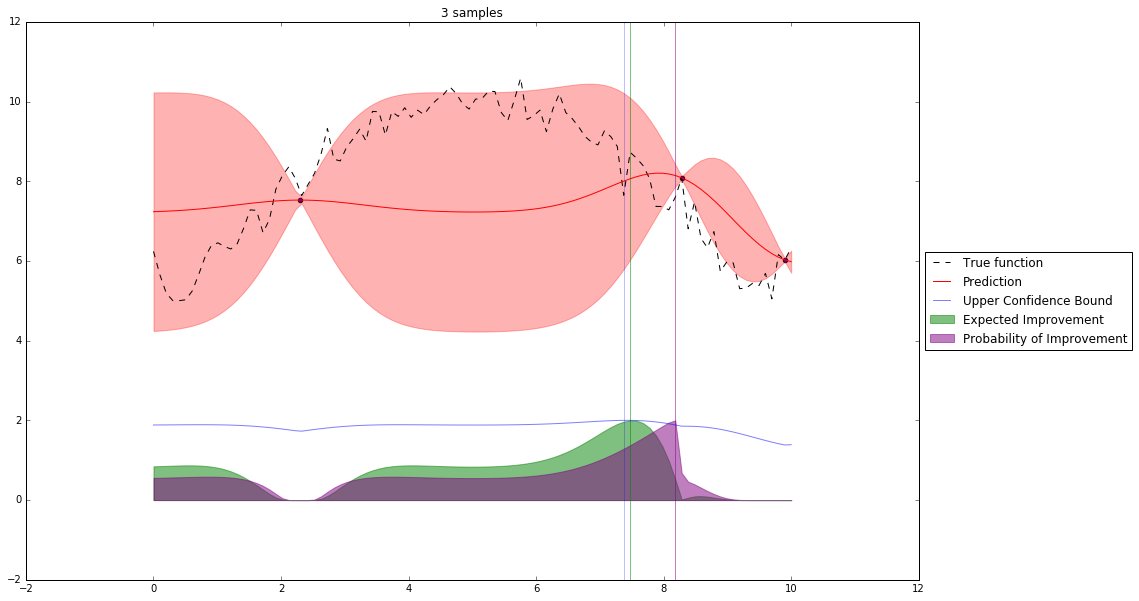
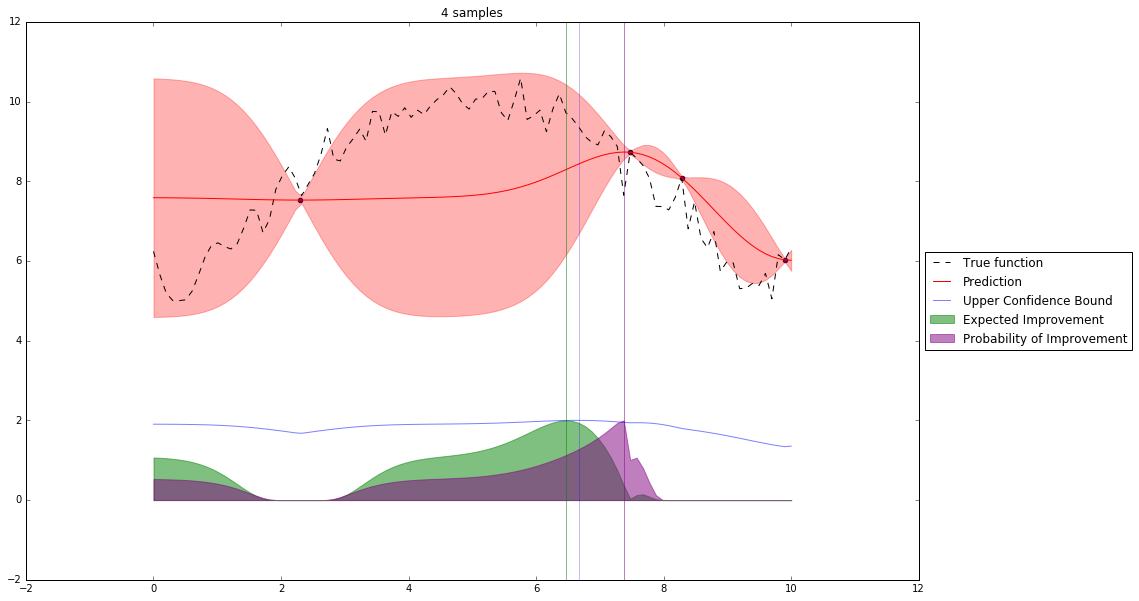
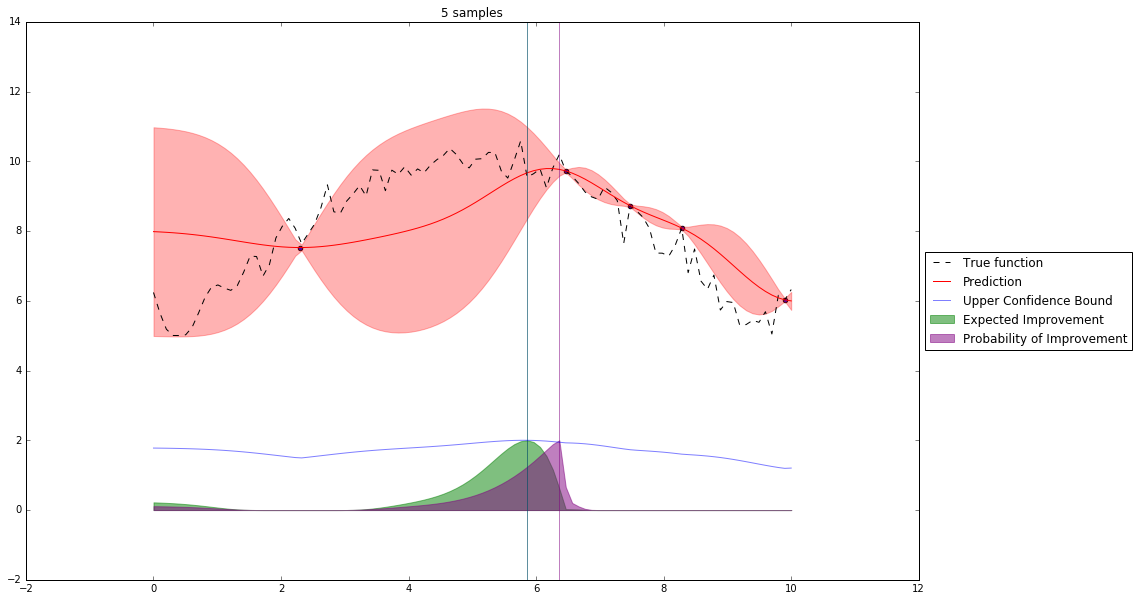
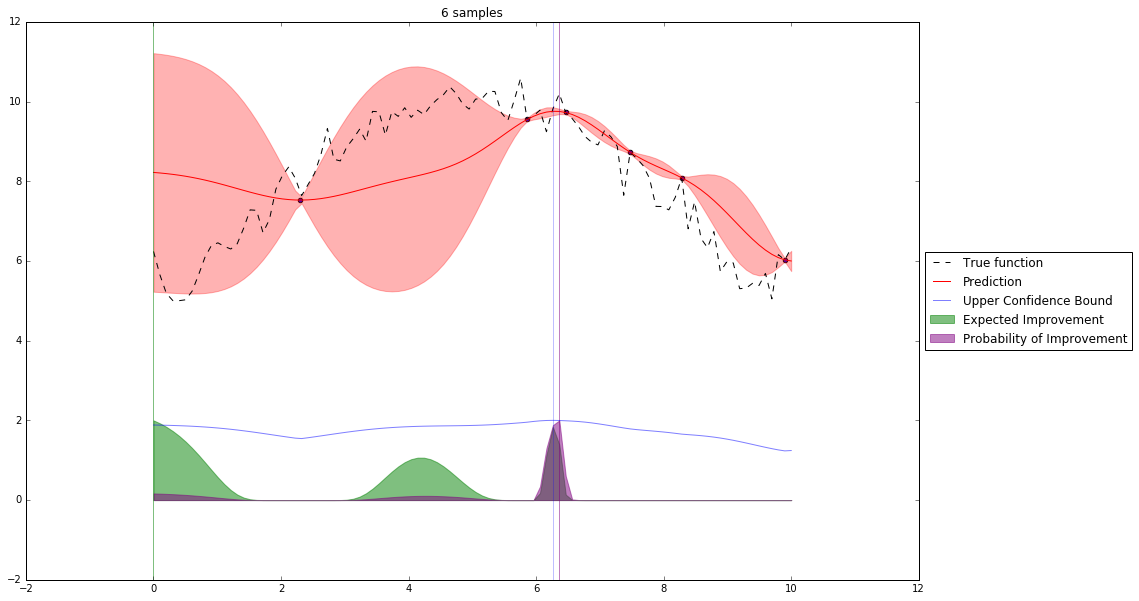
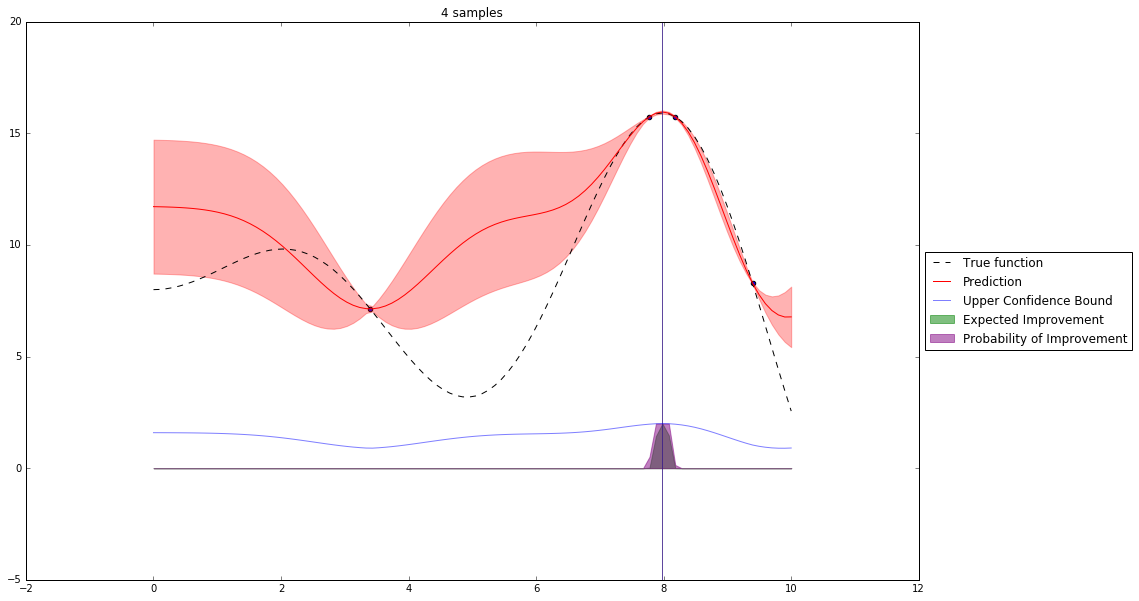
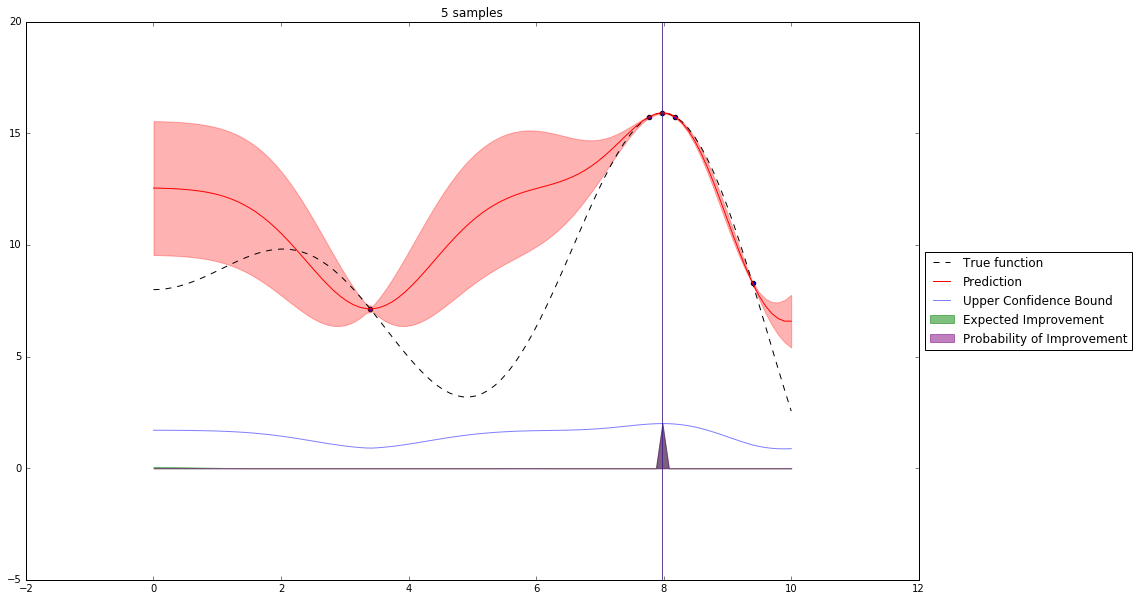
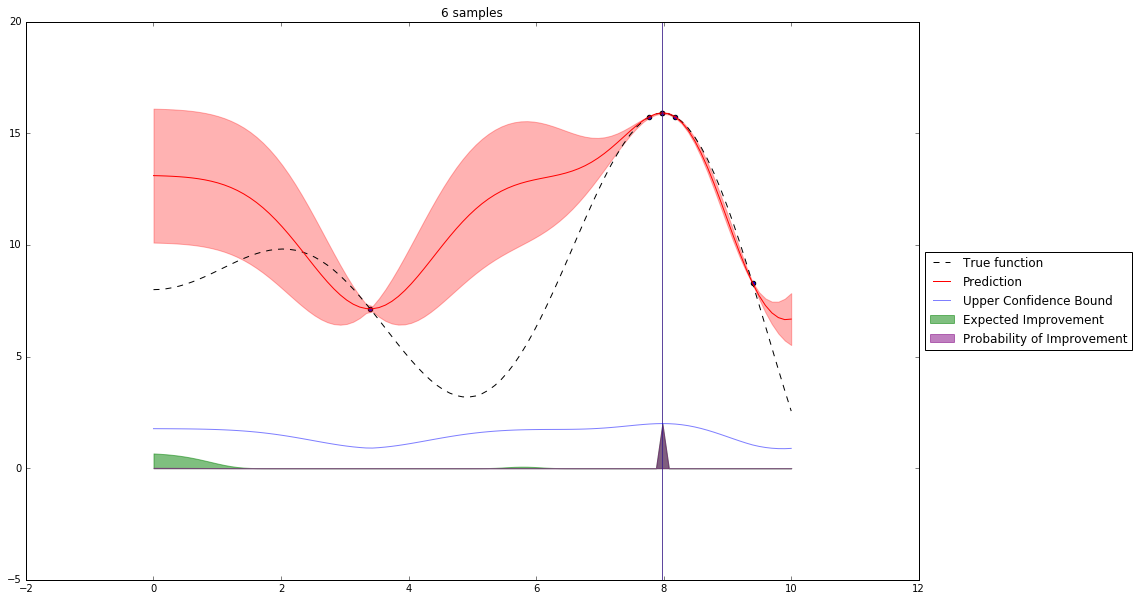
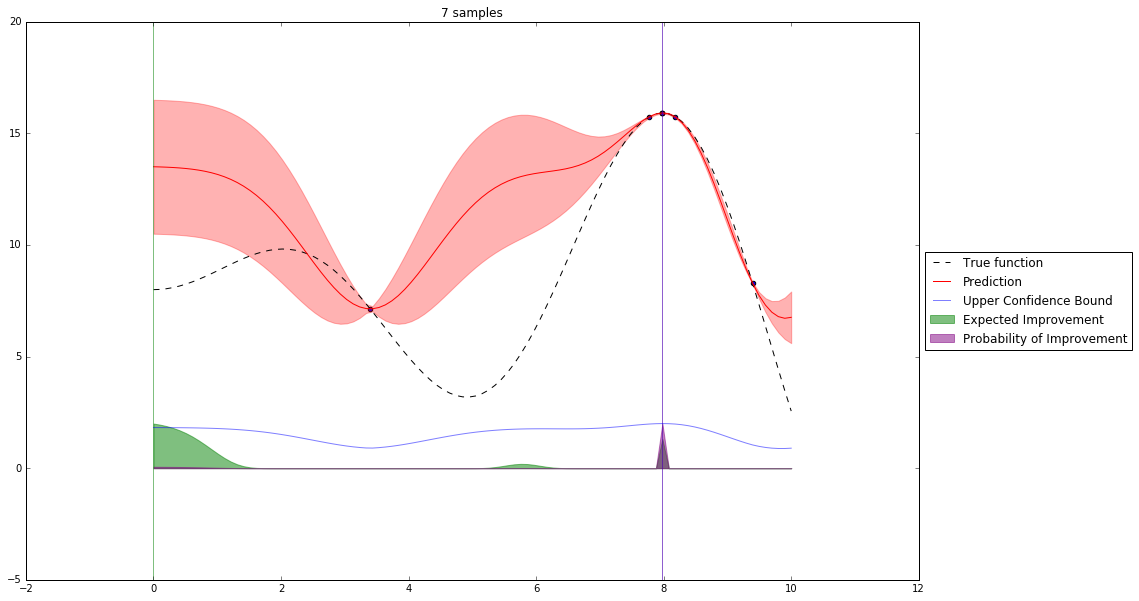
Bayesian Optimization¶
Let's denote our observations in $n^{th}$ step by $D_n$
$f \sim $ some random process e.g. $\mathcal{GP}(\mu(x), \mathbf{K}(x,x')) $
$$P(f| D_n) \propto P(D_n | f) P(f) $$So we have a posterior random process representing our beliefs about the function we observe.
What now?
We can query this posterior random process by an acquisition function
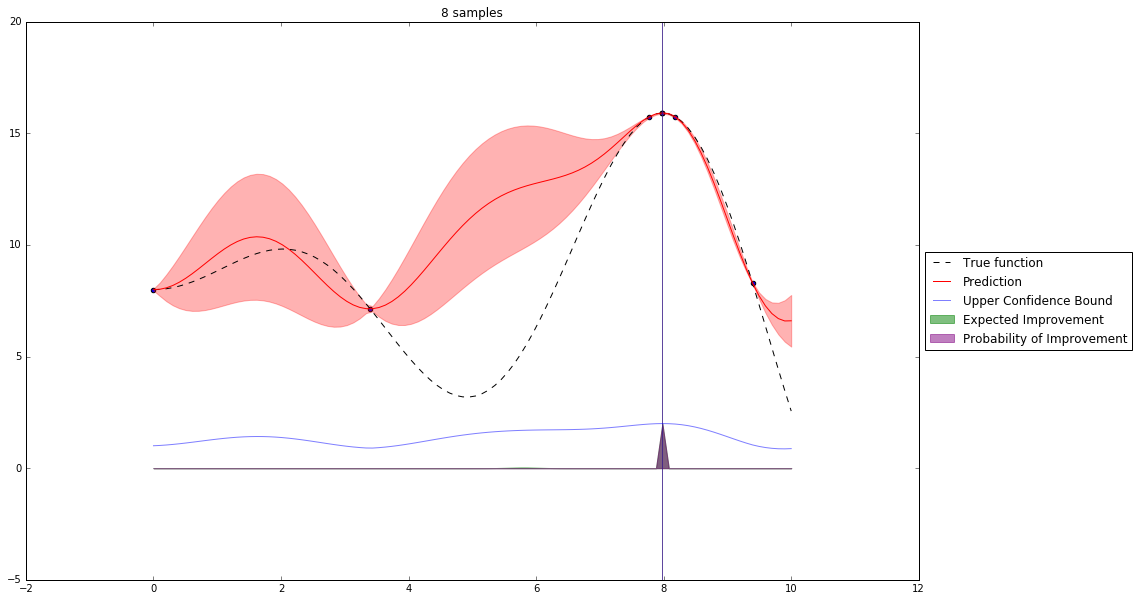
Acquisition Functions¶
Let denote $x^+$ best observed configuration so far
- Probability of Improvement
$\qquad\mathrm{PI}(x) = P(f(x) \geq f(x^+) + \xi)$
- Expected Improvement
$\qquad \mathbf{E}\mathrm{I}(x)= \mathbf{E}(\max\{0, f_{t+1}(x)-f(x^+)\}|D_t)$
- Upper Confidence Bound
$\qquad \mathrm{UCB}(x) =\mu(x) + \kappa\sigma(x)$
General Framework (SMBO)¶
M = [(x, evaluate(x)) for x in initial_sample]
while not stopping_criterium():
model = fit_model(M)
x = select_point(model)
y = evaluate(x)
M.add((x,y))
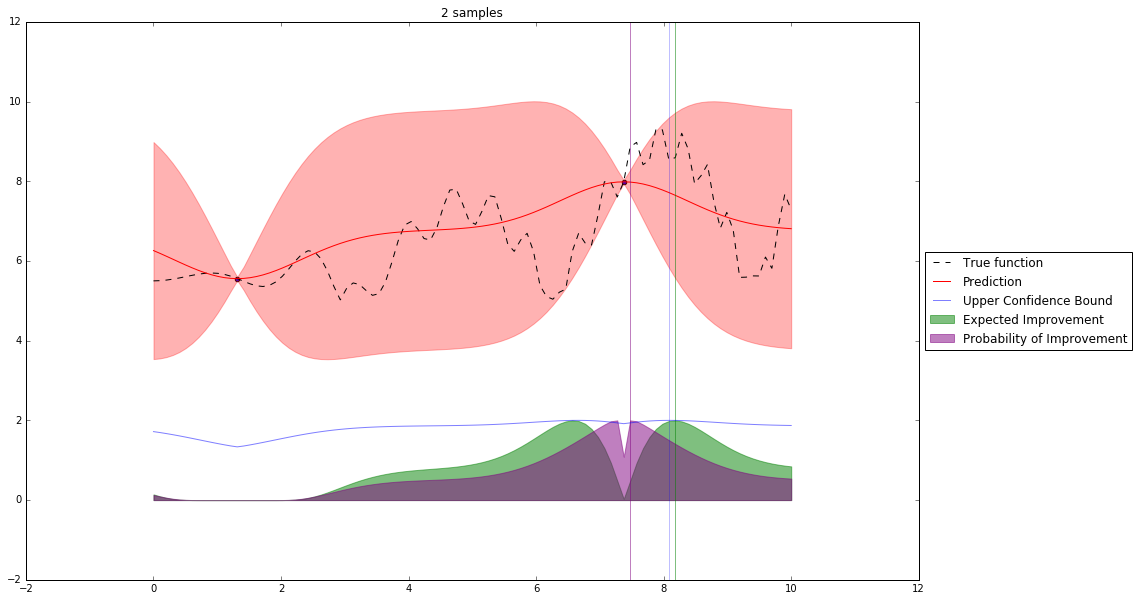
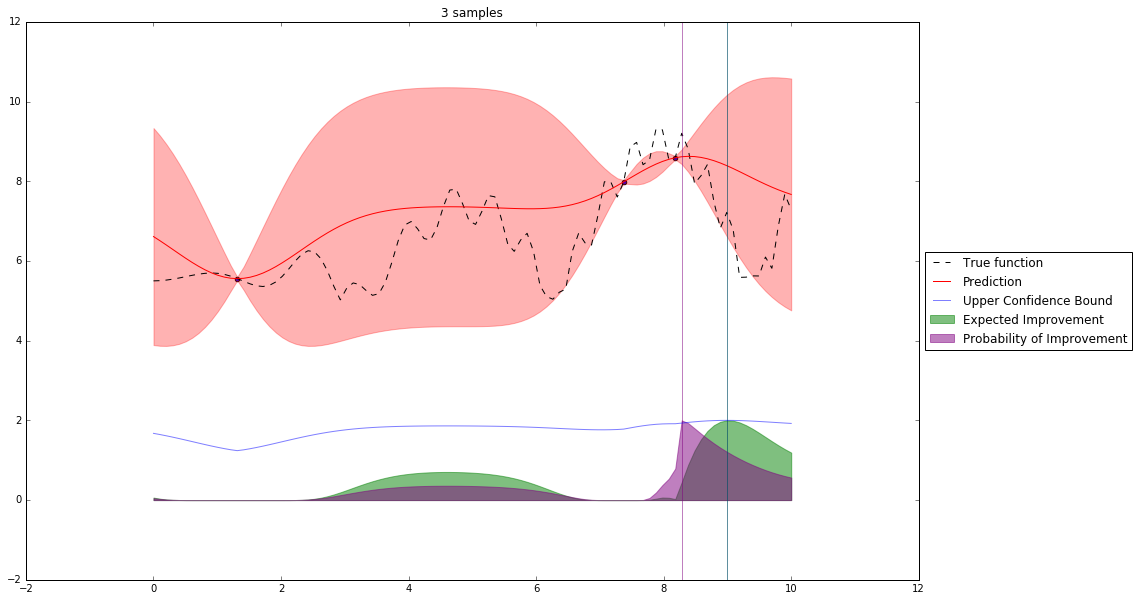
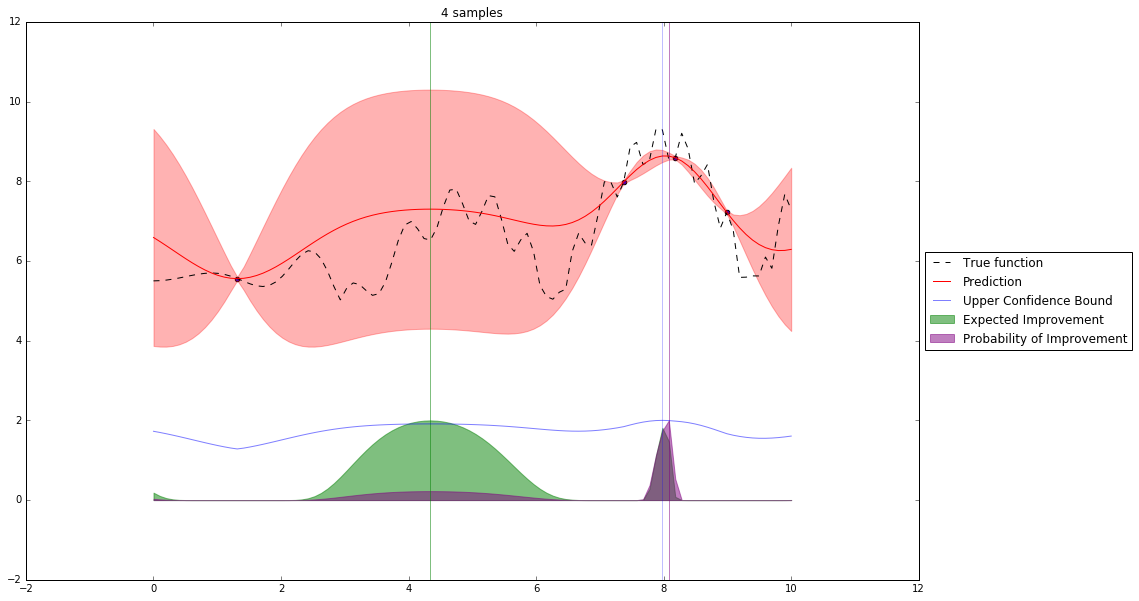
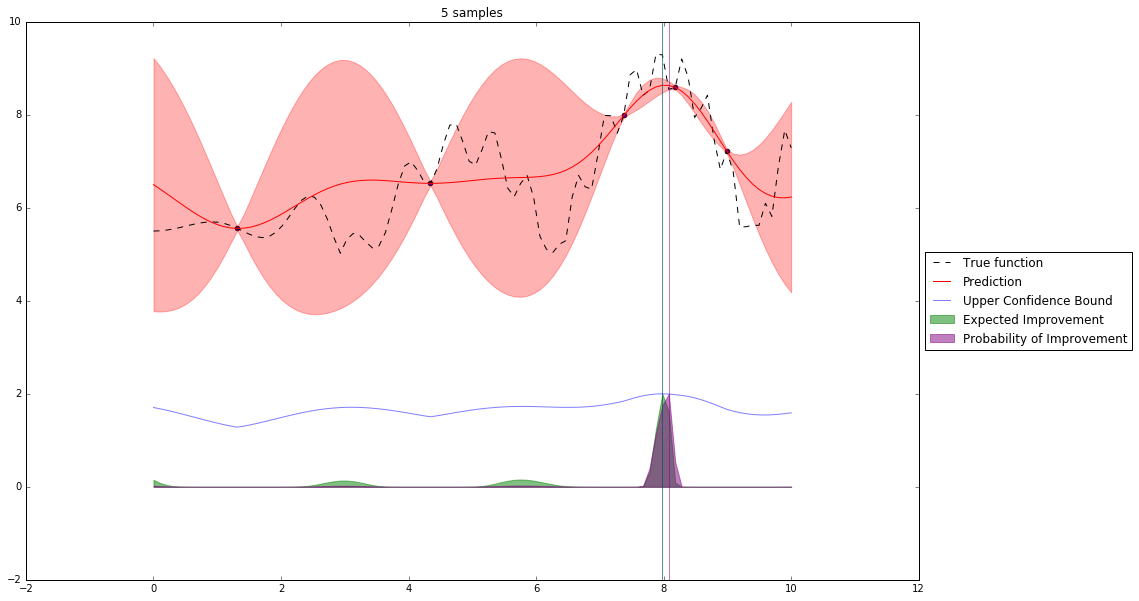
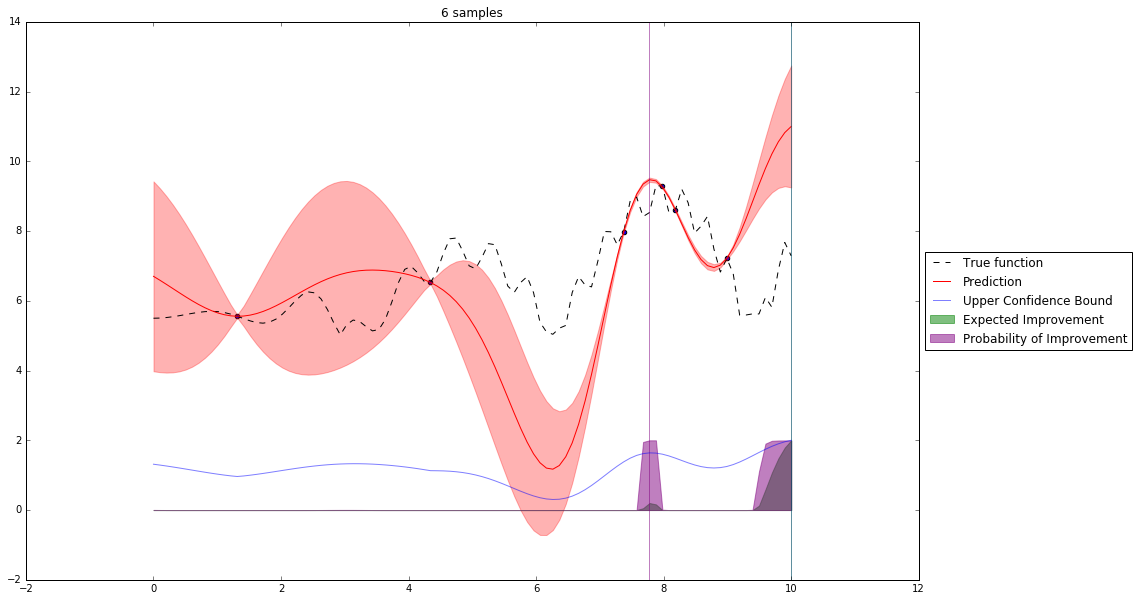
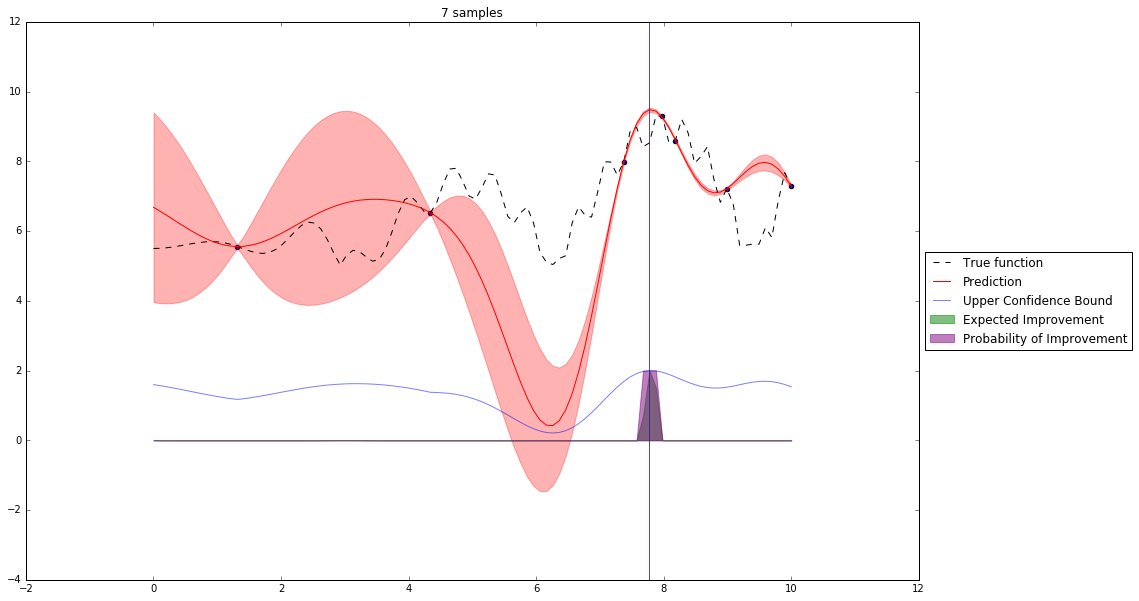
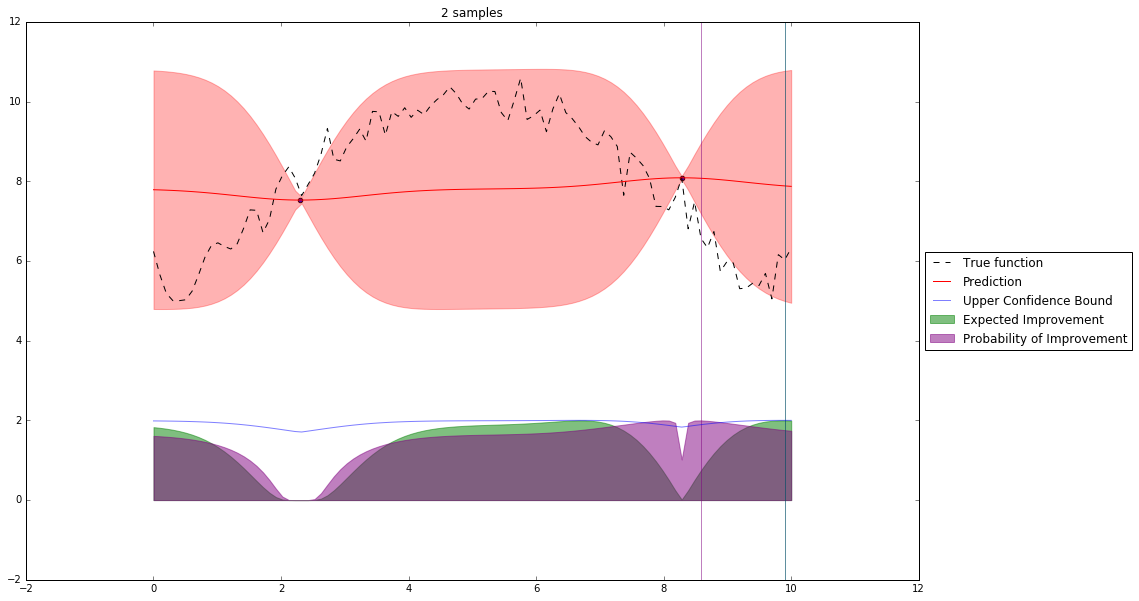
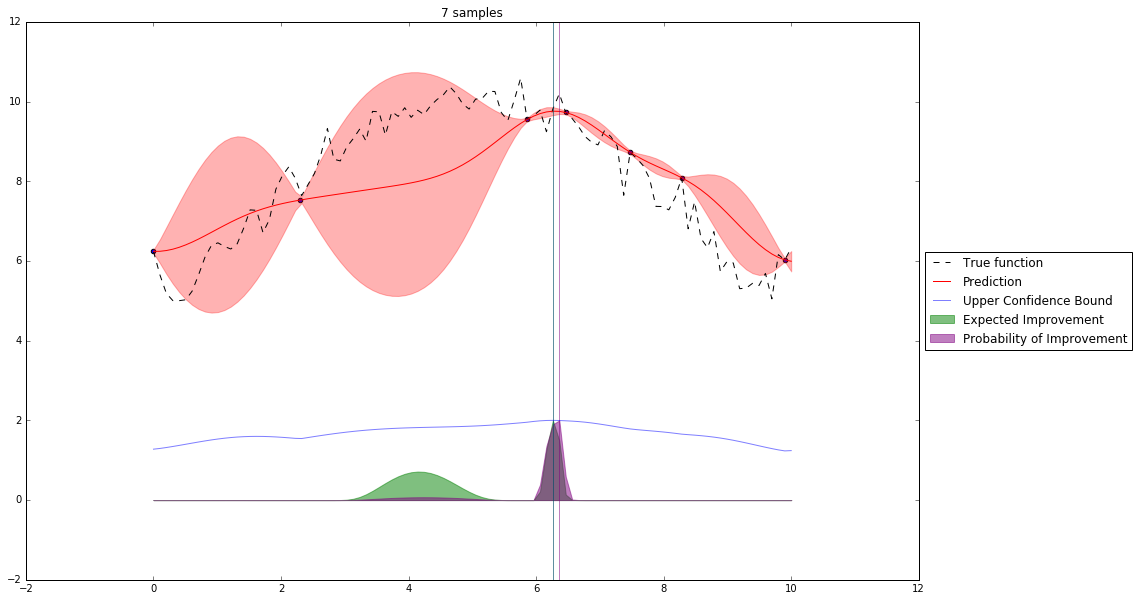
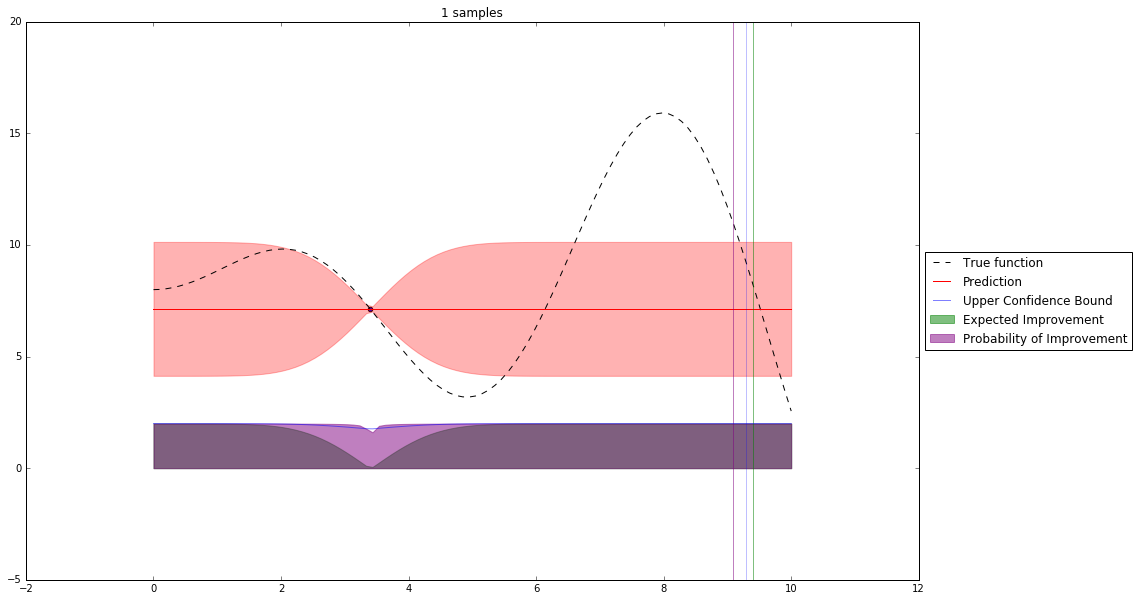
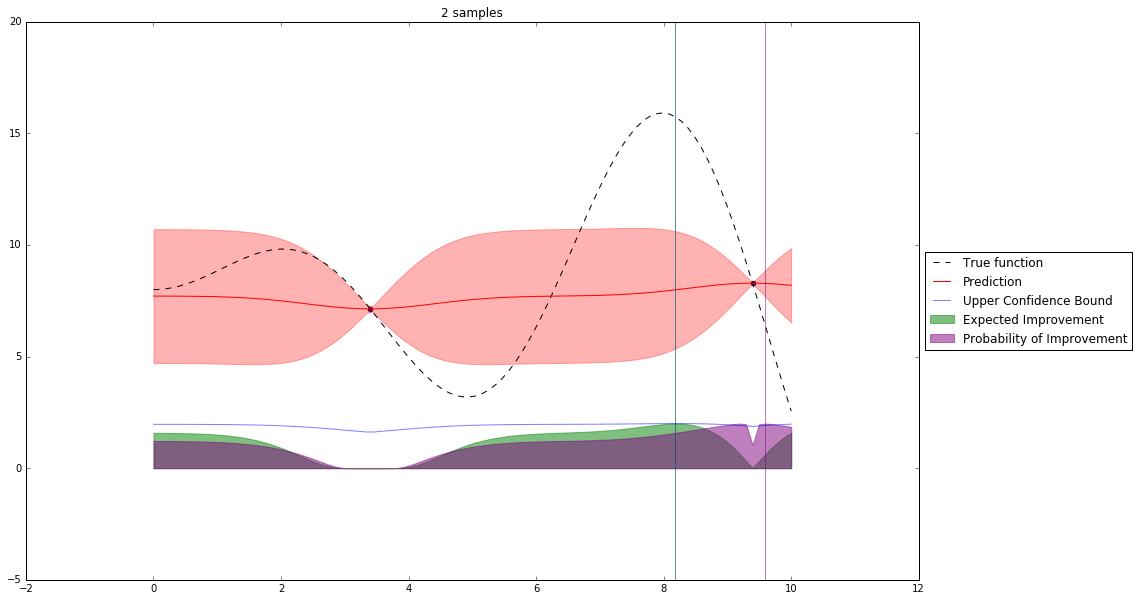
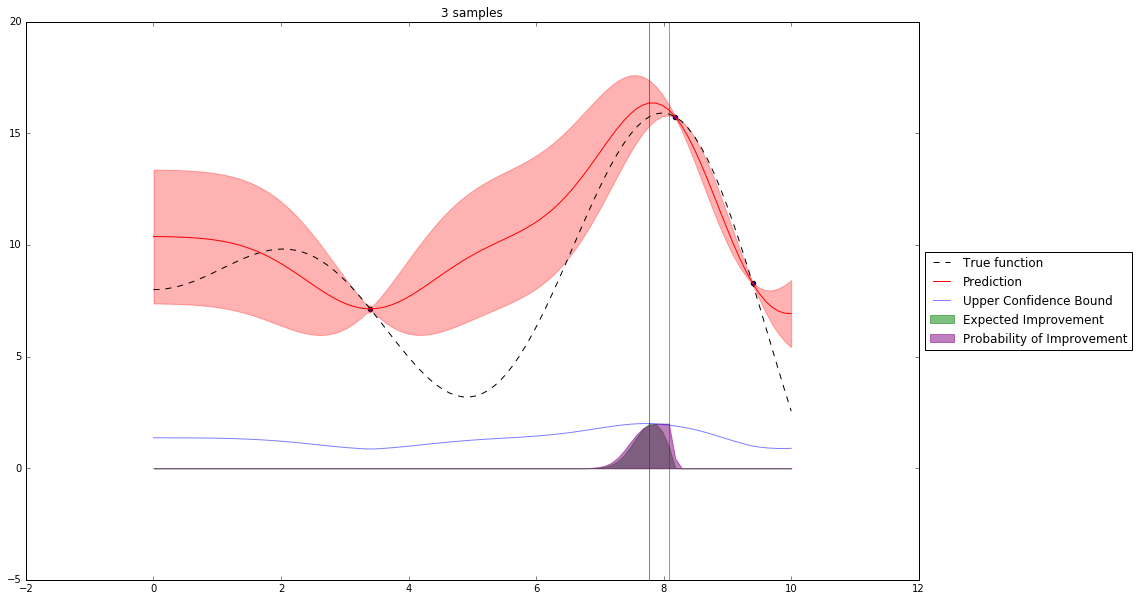
Interesting Types of Bayesian Optimization¶
Random Online Adaptive Racing (ROAR)
- uses uniform model and extends select_point()
Sequential Model-based Algorithm Configuration (SMAC)
- extends ROAR and uses random forest as a model
Tree-structured Parzen Estimator (TPE)
- each dimension is estimated separately
- density estimates are splitted in to 2 - better and worse than some value (usually some quaritile)
GP EI per second
- two independent modelled functions - cost function and time function
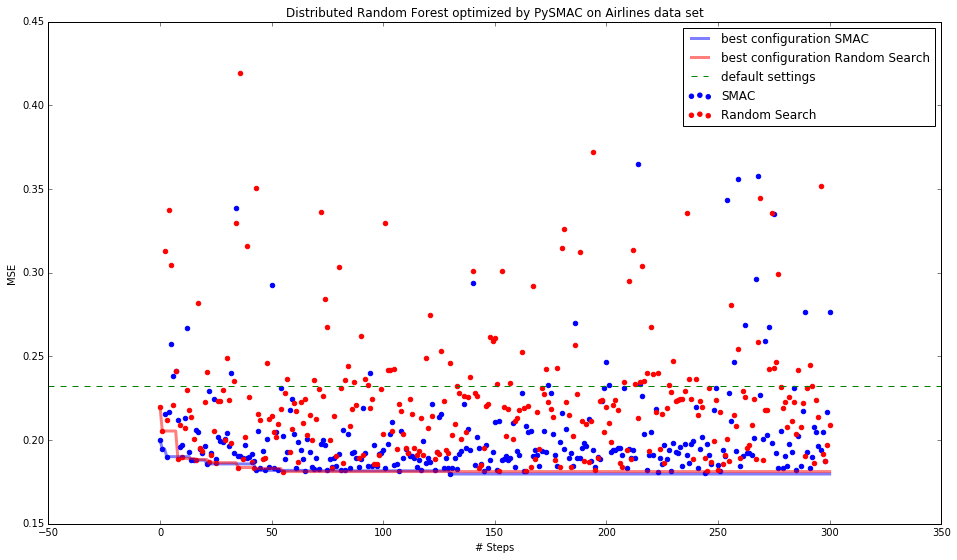
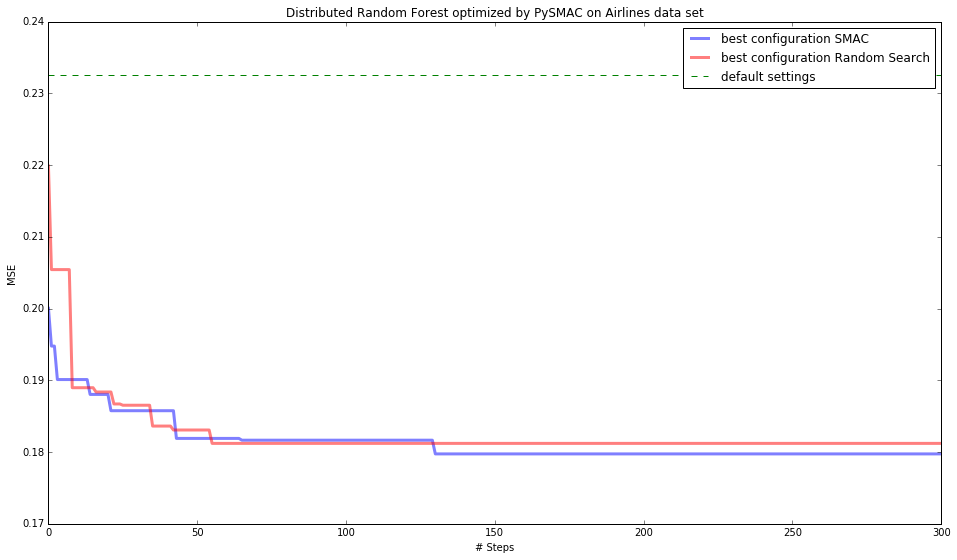
PySMAC optimizing H2O models¶
BROCHU, Eric, Vlad M. CORA a Nando DE FREITAS, 2010. A Tutorial on Bayesian Optimization of Expensive Cost Functions, with Application to Active User Modeling and Hierarchical Reinforcement Learning.
SNOEK, Jasper, Hugo LAROCHELLE a Ryan P. ADAMS. Practical Bayesian Optimization of Machine Learning Algorithms.
HUTTER, Frank, Holger H. HOOS a Kevin LEYTON-BROWN. Sequential Model-Based Optimization for General Algorithm Configuration.
Machine Learning lectures from UBC in 2013